
http://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html
---
numpy.histogram(a, bins=10, range=None, normed=False, weights=None, density=None)
#パラメータについて
a : array様シーケンス(おそらく普通のリストでもいいってことだと思う)
入力データ。aが二次元以上の場合、平坦化してから計算される。
bins : int もしくは尺のシーケンス(省略可)
intの場合、そのintは階級数(bins)の個数を規定する。(デフォルトで10階級)
シーケンスの場合、そのシーケンスの値は階級境界(bins edges)を規定する。ただし、最右端もそのシーケンスに含まれなければならない。非均等幅も可能。
range : (float, float) (省略可)
binsの最小と最大値。デフォルトでは、単純に(a.min(), a.max())が与えられる。
normed:
バグとか混乱が大きいため、numpy 2.0以降では廃止[なので訳さない。]
weights : array様シーケンス
重みの配列で、aと同じ形をしているシーケンスをとる。aのそれぞれの値は度数のカウントの際にその重み倍されて数えられる。
density : bool(省略可)
Trueにすると、度数の代わりにその階級での規定した幅の全面積が1になるような確率密度関数の値が出力される。単位幅(unity width)の階級が選ばれていない限り、度数の総和が1にならないことに注意。すなわち、確率質量関数ではない。[つまり、density=Trueにした場合は、得られた値×階級幅が相対度数になるのかな?まあ相対度数グラフならdensity=Falseで度数リストもらってから、それをデータ数で割ったほうが簡単そうだ。]
#返り値
hist : array
度数。
bin_edges : array of dtype float
階級境界の値(最右端も含む)
-------------------------------------
scipy.stats.histogram()も存在した!
何が違うのかよくわからんので、とりあえず和訳。
http://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.histogram.html
---
scipy.stats.histogram(a, numbins=10, defaultlimits=None, weights=None, printextras=False)
指定された範囲をいくつかの階級にわけ、それぞれの階級の度数を返す。
#パラメータ:
a : array様シーケンス
データの配列
numbins : int (省略可)
階級の数。デフォルトは10
defaultlimits : タプル (lower, upper) (省略可)
ヒストグラムの範囲の最小値と最大値。省略した場合は、データの範囲(max(a)-min(a))よりわずかに広めに範囲が設定される。
特に、(a.min() - s, a.max() + s),
ここで s = (1/2)(a.max() - a.min()) / (numbins - 1).
weights : array様シーケンス(省略可)
aのそれぞれの値に対する重み。デフォルトだと無し、すなわち、それぞれに1倍の比重をかける。
printextras : bool(省略可)
Trueにした場合、除外点(extra points)(設定した範囲から漏れたデータ)があるときにその数をprintする。デフォルトはFalse.
#返り値:
histogram : ndarray
それぞれの階級の度数(もしくは重み付き度数)
low_range : float
ヒストグラムの階級境界の最小値(最左端)。
binsize : float
階級幅(the size of the bins)。すべての階級は等幅である。
extrapoints : int
ヒストグラムの範囲から漏れたデータの個数
--------------------------------------
#どっちを使うべきなんだろう
とりあえず、numpyのほうは非均等階級幅が設定できるのが強み(?)でも使うことあんのか。
その自由性があるから階級境界値もシーケンスでリターンするんだね。
しかし、numpyのほうは最右端の値も度数としてカウントするという、データの階級への入れ方が非均等なのであまりすきじゃない。しかも、ヒストグラム書くときのルールである「階級境界はデータの0.5単位下にとる」というのをガン無視してるので。
そう考えると、scipyのほうがより正確。ヒストグラムの範囲をデータ範囲より若干広く取るので。さらに非均等幅の設定はできないので、返り値もシンプル。ただ、グラフ書くときはちょっとめんどくさそう。
>>> data = np.random.randint(0,10,20)
>>> data
array([0, 2, 4, 9, 1, 0, 0, 6, 7, 8, 5, 3, 9, 7, 6, 3, 4, 9, 8, 0])
>>> stats.histogram(data)
(array([ 4., 1., 1., 2., 2., 1., 2., 2., 2., 3.]), -0.5, 1.0, 0)
>>> his_f, his_amin, his_d = stats.histogram(data)[:-1]
諸々の値デフォルト(階級数10)で度数分布作ったの図。
階級境界最小値は-0.5, 階級幅は1.0から、ヒストグラムの横軸を作れるはず。
とりあえず、numpyの返り値である、bin_edgeの最右端の無いバージョンは、
>>> bin_edge = np.array([his_amin + his_d * i for i in range(np.size(his_f))])
array([-0.5, 0.5, 1.5, 2.5, 3.5, 4.5, 5.5, 6.5, 7.5, 8.5])
とすれば求まるし、階級値c(階級境界の中点)は、
>>> his_c = bin_edge + np.ones(np.size(his_f))*0.5*his_d
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
とすればよい。ここまでくれば、あとはnumpyと同様、
>>> pl.bar(his_c,his_f)

でおk。pl.xlim, pl.ylim, pl.xticks, pl.yticks などはお好みでどうぞ。
一例を下に。
import numpy as np
from scipy import stats as stats
import pylab as pl
data = np.array([0, 2, 4, 9, 1, 0, 0, 6, 7, 8, 5, 3, 9, 7, 6, 3, 4, 9, 8, 0])
bins = 10
his_f, his_amin, his_d =stats.histogram(data, numbins=bins)[:-1]
bin_edge = np.array([his_amin+his_d*i for i in range(bins)])
his_c = bin_edge + np.ones(bins)*0.5*his_d
bar_width = 0.5
pl.xlim(min(bin_edge)-0.5,max(bin_edge) + his_d + 0.5)
pl.ylim(0,max(his_f)+1)
pl.xticks(bin_edge + np.ones(bins)*bar_width*0.5, his_c)
pl.bar(bin_edge, his_f, width = bar_width)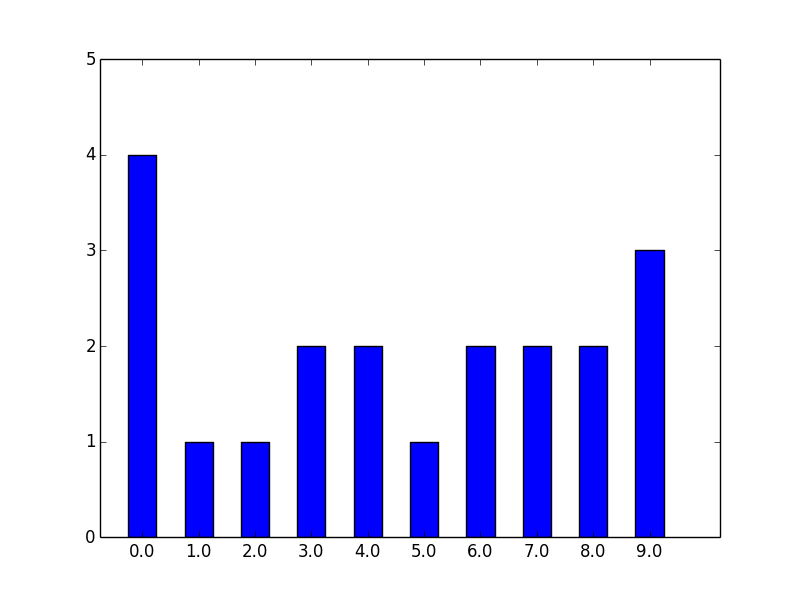
xtickでx軸の目盛りは色々変えれるはず。
階級範囲を示しておきたい(普通はこれがベターかも)なら、
xticks_label = [str(i)+"~"+str(i+his_d) for i in bin_edge]
pl.xticks(bin_edge + np.ones(bins)*bar_width*0.5, xticks_label)
としてやれば、

みたいな感じでいけます。内包表記って便利だなあ!






